by Logan Apr 27,2025
एक चीनी-विकसित मॉडल, दीपसेक एआई के उद्भव ने अमेरिकी टेक उद्योग के भीतर महत्वपूर्ण विवाद और चिंता पैदा कर दी है। डीपसेक ने अपने स्वयं के मॉडल को प्रशिक्षित करने के लिए ओपनईएआई के डेटा का उपयोग करने के संदेह में उद्योग के नेताओं और राजनीतिक आंकड़ों से समान रूप से प्रतिक्रिया दी है। डोनाल्ड ट्रम्प ने डीपसेक को यूएस टेक सेक्टर के लिए "वेक-अप कॉल" के रूप में लेबल किया है, विशेष रूप से एनवीडिया ने अपने स्टॉक मूल्य में 16.86% की गिरावट के बाद बाजार मूल्य में $ 600 बिलियन की गिरावट का अनुभव किया है-वॉल स्ट्रीट के इतिहास में सबसे बड़ा एकल-दिन का नुकसान। Microsoft, मेटा प्लेटफ़ॉर्म, Google की मूल कंपनी वर्णमाला, और डेल टेक्नोलॉजीज जैसे अन्य तकनीकी दिग्गजों ने भी अपने स्टॉक वैल्यू में गिरावट देखी, जो कि डीपसेक द्वारा उत्पन्न प्रतिस्पर्धी खतरे के बारे में व्यापक बाजार की बेचैनी को दर्शाती है।
डीपसेक का आर 1 मॉडल, ओपन-सोर्स डीपसेक-वी 3 पर बनाया गया है, जो कि CHATGPT जैसे पश्चिमी AI मॉडल के लिए एक लागत प्रभावी विकल्प की पेशकश करने का दावा करता है, कथित तौर पर काफी कम कंप्यूटिंग शक्ति की आवश्यकता होती है और केवल $ 6 मिलियन के लिए प्रशिक्षित किया गया था। इस दावे ने न केवल भारी निवेशों को चुनौती दी है जो अमेरिकी टेक कंपनियां एआई में बना रही हैं, बल्कि डीपसेक को भी यूएस फ्री ऐप डाउनलोड चार्ट के शीर्ष पर ले गई हैं, इसकी प्रभावशीलता के बारे में चर्चा द्वारा ईंधन।
इन घटनाक्रमों के जवाब में, Openai और Microsoft यह जांच कर रहे हैं कि क्या DeePseek ने Openai के API का उपयोग Openai के मॉडल को अपने आप में एकीकृत करने के लिए किया था, एक अभ्यास जिसे आसवन के रूप में जाना जाता है। यह तकनीक, जिसमें अधिक उन्नत लोगों से डेटा निकालकर AI मॉडल को प्रशिक्षित करना शामिल है, को Openai की सेवा की शर्तों द्वारा स्पष्ट रूप से प्रतिबंधित किया गया है। Openai ने अपनी बौद्धिक संपदा की रक्षा करने के लिए अपनी प्रतिबद्धता पर जोर दिया है और इस तरह की प्रथाओं से अपनी तकनीक को सुरक्षित रखने के लिए अमेरिकी सरकार के साथ सहयोग कर रहा है।
स्थिति ने कुछ तिमाहियों से तेज आलोचना और पाखंड के आरोपों को आकर्षित किया है। टेक पीआर और लेखक एड ज़िट्रॉन ने Openai की शिकायतों की विडंबना पर प्रकाश डाला, Catgpt को प्रशिक्षित करने के लिए कॉपीराइट इंटरनेट सामग्री का उपयोग करने का अपना इतिहास दिया। Openai ने पहले तर्क दिया है कि कॉपीराइट सामग्री के बिना AI मॉडल को प्रशिक्षित करना "असंभव" है, एक ऐसा रुख जिसने AI प्रशिक्षण डेटा की नैतिकता और वैधता के बारे में चल रही बहस को हवा दी है।
AI प्रशिक्षण डेटा के आसपास का विवाद Openai और Microsoft के खिलाफ कानूनी कार्यों के साथ बढ़ गया है। न्यूयॉर्क टाइम्स ने दिसंबर 2023 में एक मुकदमा दायर किया, जिसमें एआई उत्पादों को विकसित करने के लिए अपनी सामग्री के "गैरकानूनी उपयोग" का आरोप लगाया गया। इसी तरह, जॉर्ज आरआर मार्टिन सहित 17 लेखकों के एक समूह ने सितंबर 2023 में कानूनी कार्रवाई शुरू की, जिसमें ओपनई ने "एक बड़े पैमाने पर व्यवस्थित चोरी" का आरोप लगाया। ये मुकदमे एआई विकास में कॉपीराइट सामग्री का उपयोग करने के विवादास्पद मुद्दे को रेखांकित करते हैं, ओपनआईएआई ने अपनी प्रथाओं को "उचित उपयोग" के रूप में बचाव किया है।
इन कानूनी लड़ाइयों के बीच, अगस्त 2023 में जिला न्यायाधीश बेरिल हॉवेल द्वारा एक अमेरिकी कॉपीराइट कार्यालय के फैसले को बरकरार रखा गया था कि कॉपीराइट संरक्षण में मानव रचनात्मकता की आवश्यकता पर जोर देते हुए, एआई-जनित कला को कॉपीराइट नहीं किया जा सकता है। यह फैसला एआई, बौद्धिक संपदा और प्रौद्योगिकी विकास के भविष्य के बारे में चल रही चर्चाओं के लिए जटिलता की एक और परत जोड़ता है।

एंड्रॉइड एक्शन-डिफेंस
Gotham Knights: Rumored Nintendo Switch 2 Debut
इमर्सिव एफपीएस "आई एम योर बीस्ट" का शानदार नया ट्रेलर लॉन्च हुआ
ब्लैक ऑप्स 6 जॉम्बीज: ऑल सिटाडेल डेस मोर्ट्स ईस्टर एग्स
मोबाइल लेजेंड्स: जनवरी 2025 रिडीम कोड जारी
डिज्नी का 'पिक्सेल आरपीजी' मोबाइल लॉन्च के लिए गेमप्ले का अनावरण करता है
गरेना का फ्री फायर हिट फुटबॉल एनीमे ब्लू लॉक के साथ सहयोग कर रहा है!
एंड्रॉइड फ्लोटोपिया का स्वागत करता है: एक मनोरम पशु क्रॉसिंग-प्रेरित गेम

Fast Math Puzzles & Riddles
डाउनलोड करना
Slotigo - Online-Casino
डाउनलोड करना
Mindsweeper: Puzzle Adventure
डाउनलोड करना
Escape From Benjamin's Room
डाउनलोड करना
Moe Kyun Maniacs 0
डाउनलोड करना
Rottytops’ Raunchy Romp XXX Parody – Part 2
डाउनलोड करना
Summer Scent
डाउनलोड करना
Warnament
डाउनलोड करना
Rummy Club
डाउनलोड करना
"अमेज़ॅन स्लैश की कीमत 63" LG C4 4K OLED टीवी से $ 1,397: PS5 के लिए आदर्श "
Apr 27,2025

Fortnite अध्याय 6 सीज़न 2: सोने की भीड़ को सक्रिय करना
Apr 27,2025

मॉन्स्टर हंटर विल्ड्स के लिए पालिको भाषा गाइड बदलें
Apr 27,2025

क्या आपको हत्यारे की पंथ छाया में निर्देशित अन्वेषण मोड चालू करना चाहिए?
Apr 27,2025
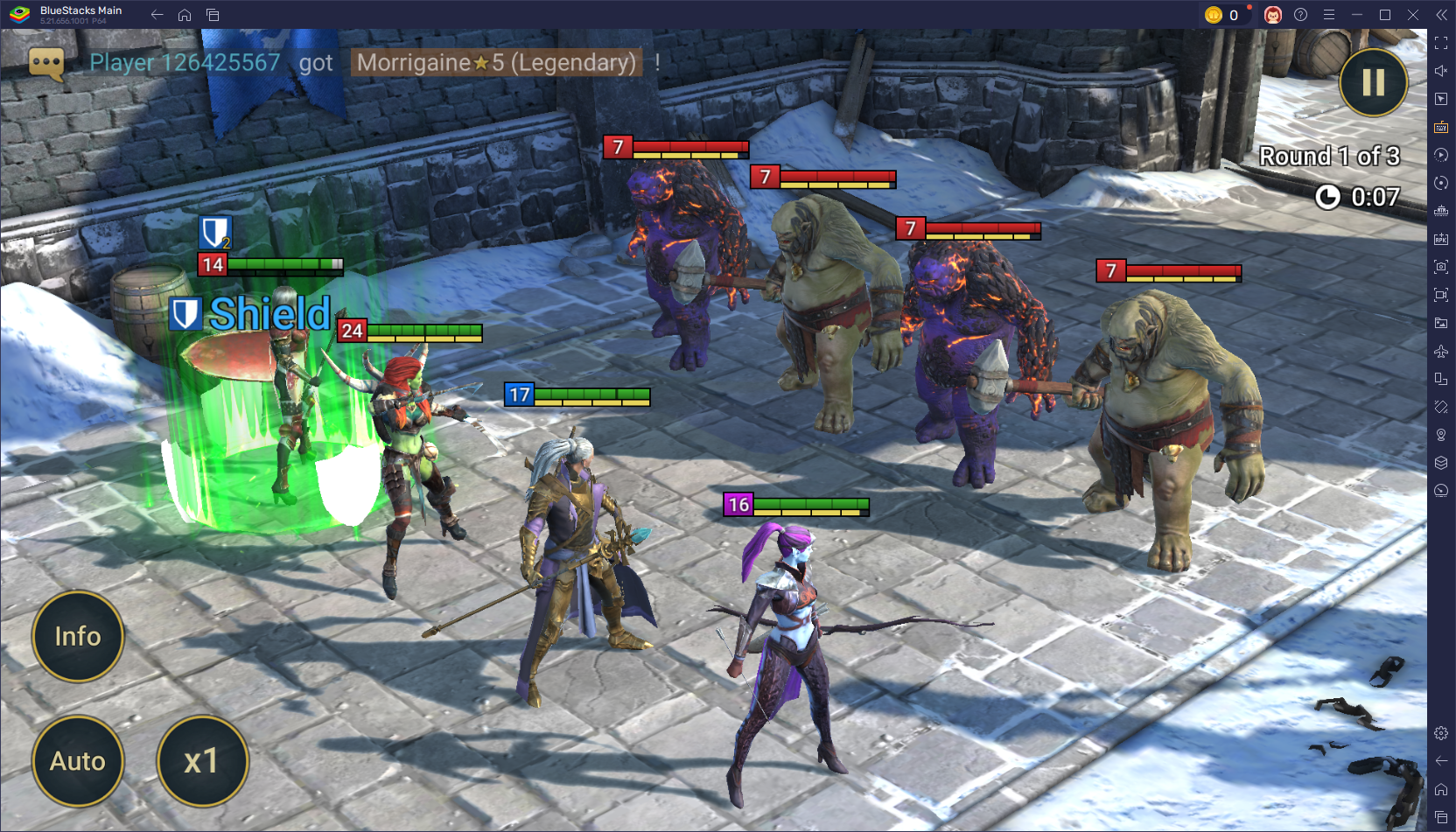
RAID: शैडो लीजेंड्स - चैंपियन बफ्स एंड डेबफ्स ने समझाया
Apr 27,2025
 वर्ग
वर्ग 




